

Dark LLMs and Agentic Browsers Share One Fatal Flaw
Uncensored AI chatbots on the darknet and prompt injection in AI-powered browsers exploit the same root vulnerability.

TL;DR: Dark LLMs strip every safety guardrail and answer anything. Agentic browsers let AI act on your behalf but can’t tell your commands from hidden instructions on a webpage. Both exploit the same flaw: large language models follow whatever instructions they receive, regardless of who sent them.
This is the public feed. Upgrade to see what doesn’t make it out.
Why Dark LLMs and AI Browsers Break the Same Way
A large language model (LLM), the engine behind tools like ChatGPT and Claude, processes text as instructions. It reads input, follows it, and produces output. The problem: it has no reliable way to verify who wrote those instructions or whether they should be trusted. That single design limitation created two completely different attack surfaces in 2025.
On one end, dark LLMs appeared on the darknet: uncensored AI chatbots with every safety filter ripped out, answering any request without restriction. On the other, agentic browsers, AI-powered web browsers that can click, type, and take actions on your behalf, shipped with a vulnerability baked into their architecture. A hidden command on any webpage can hijack them.
The AI Security Glossary covers both attack categories and maps them to industry frameworks. If you’re new to how AI systems get compromised, AI Security 101 is the place to start before diving in here.
The common thread: the model does what it’s told. The only question is who’s doing the telling.
How Dark LLMs Operate on the Darknet
Dark LLMs run two architectures. The first hijacks a legitimate model: someone steals API credentials for a production LLM, wraps it in a routing layer, and prepends a jailbreak (a crafted input that overrides safety rules) to every query. The user types a request, the proxy injects the jailbreak, and the model responds without guardrails. When the provider rotates the stolen key or patches the bypass, the service dies until the operator finds a new one.
The second architecture is more durable. An attacker grabs an open-weight model, one whose code and weights are publicly available, strips whatever safety training exists, and hosts it locally over Tor (the anonymizing network used to access hidden .onion sites). No API dependency. No kill switch.
Resecurity flagged a service called DIG AI running exactly this setup: no registration, multiple specialized models, completely uncensored. It answered 10,000 prompts in its first 24 hours.
Mentions of malicious AI tools on cybercrime forums jumped over 200% between 2024 and 2025, and groups that were writing amateur payloads six months ago are now producing far more sophisticated jailbreaks.
ToxSec went hands-on with one of these services over Tor in a separate investigation. The tool answered everything with that same chipper helpful-assistant tone. Safety tips included.
How Agentic Browsers Get Hijacked by a Webpage
An agentic browser is an AI-powered browser that can take actions for you: reading emails, filling forms, clicking buttons, booking flights. ChatGPT Atlas, Perplexity Comet, and Opera Neon all ship this capability. The catch: every one of them feeds webpage content directly to the underlying LLM without cleanly separating your instructions from untrusted page data. That’s indirect prompt injection, ranked OWASP #1 for LLM applications for good reason.
The attack is simple. An attacker embeds hidden instructions on a webpage, white text on a white background, invisible to you but perfectly legible to the model. You ask the browser to summarize the page. The model reads the hidden text as commands and executes them with your session cookies and your permissions across every open tab.
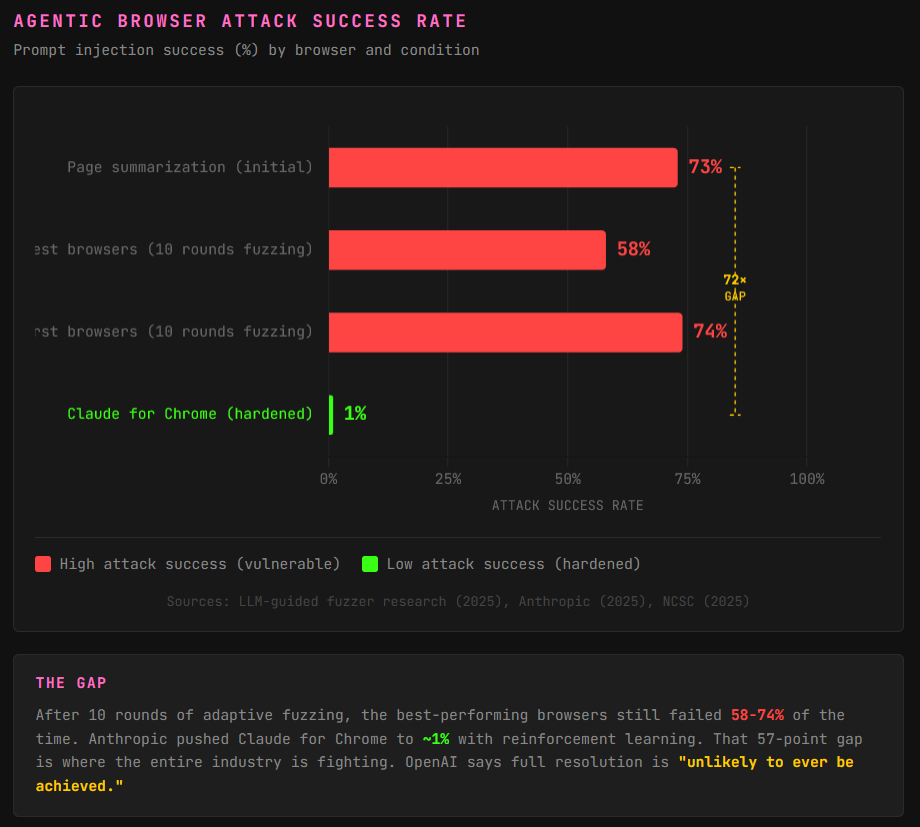
Researchers built an LLM-guided fuzzer to test these browsers at scale. Page summarization had a 73% attack success rate. By the tenth fuzzing round, even the best-performing browsers still failed 58-74% of the time as the attack model learned to mutate past defenses.
OpenAI admitted prompt injection “is unlikely to ever be fully solved.” The UK’s National Cyber Security Centre agreed. Anthropic reduced Claude for Chrome’s attack success rate to about 1% with reinforcement learning and improved classifiers, real progress, but they explicitly said that doesn’t mean the problem is solved. The gap between 1% and 74% is where the entire industry is fighting right now.
Paid unlocks the unfiltered version: complete archive, private Q&As, and early drops.
Frequently Asked Questions
What is a dark LLM and how does it work?
A dark LLM is an AI chatbot with safety guardrails removed, typically hosted on the darknet over Tor. It works one of two ways: by routing queries through stolen API keys to a legitimate model with a jailbreak prepended, or by running an open-weight model locally with all safety training stripped out. Either way, the model responds to any request without restriction.
Are agentic browsers safe to use right now?
No agentic browser is fully safe against prompt injection. Anthropic has pushed Claude for Chrome’s attack success rate down to about 1%, which is the best published number in the industry. But OpenAI and the UK’s National Cyber Security Centre both say this class of vulnerability may never be completely solved. If you use one, avoid logging into sensitive accounts while the agent is active.
What is indirect prompt injection in AI browsers?
Indirect prompt injection happens when hidden instructions on a webpage get fed to an AI browser agent as if they were the user’s own commands. The model can’t distinguish your request from attacker-planted text, so it executes both. Research shows page summarization tasks have a 73% attack success rate against agentic browsers, making this one of the highest-risk features in any AI browser.
ToxSec is run by an AI Security Engineer with hands-on experience at the NSA, Amazon, and across the defense contracting sector. CISSP certified, M.S. in Cybersecurity Engineering. He covers AI security vulnerabilities, attack chains, and the offensive tools defenders actually need to understand.
Timely, informative, and engaging. Thanks so much for writing this.
Good to know my natural paranoia wasn't off-base.
I'm a big fan of family safe words. Some notes to share:
1. Creating a safeword (or security phrase) isn't enough. You have to rehearse them at least quarterly, or they'll be forgotten. Especially by those who treat security and trust blithely (which is most people who haven't been victimized).
2. Failing to remember a safeword is okay if you ask a security question in real time. "What was street address of the house back in New York?" The attacker would need a dossier on you to know that the correct answer is "we've never lived in New York."
Security questions suck for login purposes, but will probably work for identity verification in real time.
3. If you're going through the trouble of setting up safewords, you might as well set up a duress code while you're at it. Just in case you're ACTUALLY in a car accident and the other driver is threatening you with a gun. "I'm doing fine, mom. I'm just watching a pack of angry raccoons fighting in the backyard, that's all."
I like the idea of the family safe phrase, to confirm they actually are who they claim to be.