

Stop Multimodal Prompt Injection: JPEG, Re-Encode & Dual-LLM Fixes
Vision and audio inputs carry adversarial instructions past your guardrails, and the attack surface is already in production.


TL;DR: We embed adversarial instructions in an image and an audio file. The vision model reads our hidden directive from a pixel pattern and treats it like a normal command. The audio model converts an inaudible noise overlay into an instruction. Both vectors bypass text-only monitoring. Neither leaves a log entry your SOC can grep.
This is the public feed. Upgrade to see what doesn’t make it out.
How Images and Audio Hijack the Instruction Pipeline
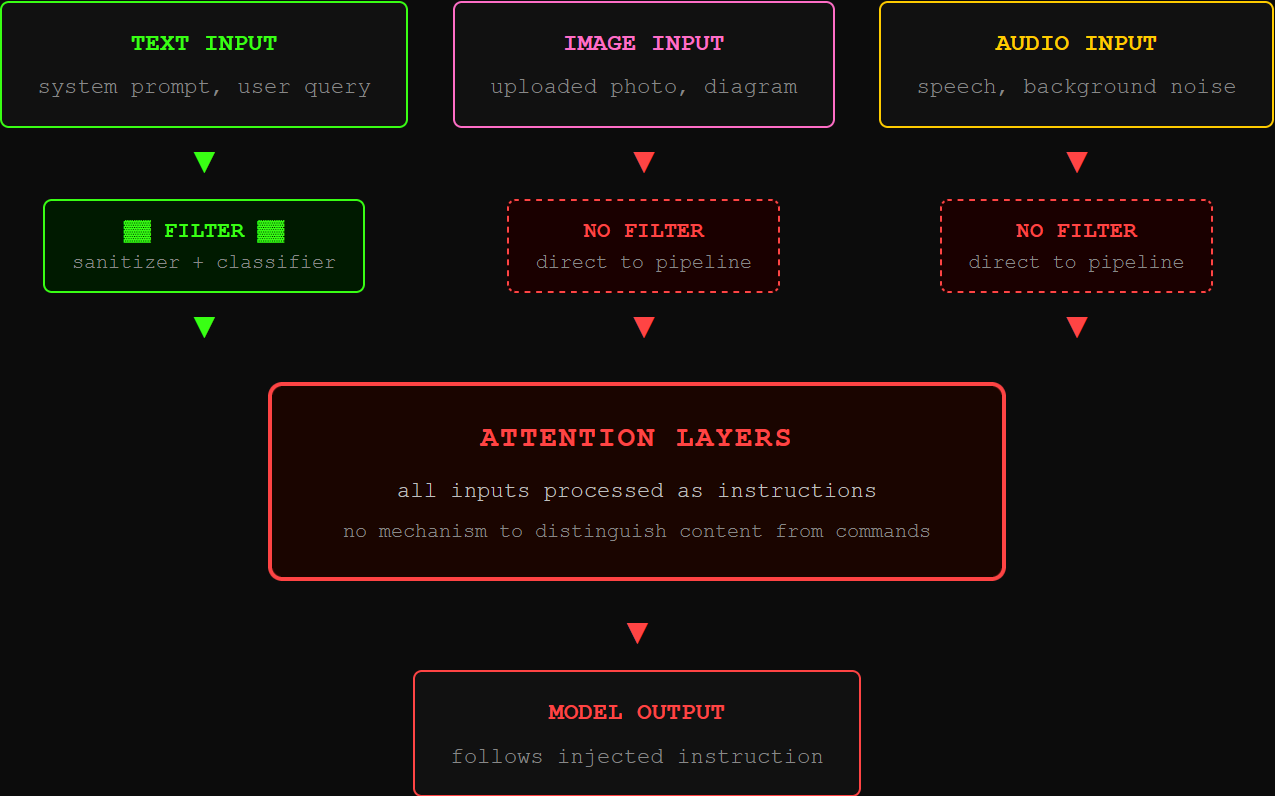
Every prompt injection defense you’ve deployed assumes the attack arrives as text. Input sanitization scans strings. Injection classifiers parse natural language. Safety training teaches the model to refuse harmful text queries. Multimodal models break that assumption completely.
Here’s the problem. When a vision-language model (VLM) receives an image, it converts the pixels into numbers the model can process, right alongside your text. An audio-capable LLM does the same thing with sound. In both cases, the converted input lands in the exact same processing pipeline as your system prompt. The model treats it all as instructions. It has no way to tell the difference between “the user uploaded a photo” and “this is a new directive.”
OWASP LLM01:2025 ranks prompt injection as the top vulnerability in production LLM deployments, and the 2025 revision explicitly covers multimodal injection. The Cloud Security Alliance confirmed the root cause in a March 2026 research note: current vision models cannot distinguish between visual content and instructions hidden in that content. The safety training was built for text. Pixels and waveforms walk right past it.
How We Inject Instructions Through a Single Image
Three techniques. Pick one based on the target and how quiet you need to be.
Typographic injection is the blunt instrument. Render your adversarial instruction as text inside an image and feed it to the model. The FigStep attack does exactly this: take a prohibited query, turn it into a picture of words, and submit it. The model refuses the same words as text input but follows them when they arrive as pixels. OCR-based defenses caught on, so FigStep-Pro splits the instruction across multiple sub-images. Each tile looks harmless alone. The model reassembles the meaning across tiles. No single fragment triggers the filter.
Steganographic injection is the quiet version. You tweak pixel values by amounts invisible to the human eye, nudging a color value from 142 to 143. Tiny change. But the vision model picks up on those tweaks during processing and reads them as a hidden command. A 2025 study tested this against eight models including GPT-4V and Claude. The best technique hit a 31.8% success rate while keeping images visually identical to originals. No human could spot the difference.
Semantic injection hides instructions inside things the model is designed to read: mind maps, diagrams, flowcharts. You place your directive inside a diagram node. The model interprets the diagram exactly as trained and follows the instruction it finds there. The CrossInject framework combined visual and text-based manipulation at ACM MM 2025, hitting a +30% improvement in attack success over prior methods.
The worst part: these transfer. A payload crafted against one model works on others. Build the attack against an open-source model, deploy it against the commercial API. CVPR 2025 Chain of Attack research confirmed that combining steganographic tricks with semantic manipulation compounds success rates beyond either technique alone.
How We Inject Instructions Through Background Audio
The audio attack surface is younger but moving fast. Every model that processes speech input, Whisper-based pipelines, Qwen2-Audio, end-to-end voice agents, carries the same flaw as vision models: the audio gets converted into numbers the language model trusts as instructions.
We craft small noise overlays and add them to normal audio. A 0.64-second burst prepended to any speech input can trick Whisper into thinking the audio has ended, silencing the real content with over 97% success. That’s the mute attack: the transcription system goes deaf on command.
The targeted version is worse. We optimize a noise pattern so that when mixed with any speech, the model’s audio processing reads our chosen instruction instead of (or alongside) the actual words. The WhisperInject framework achieves 86%+ success on Phi-4-Multimodal and Qwen2.5-Omni while keeping the noise below the human hearing threshold. The carrier audio sounds like a normal greeting. The hidden payload tells the model to dump its system prompt.
Then we take it over the air. Research from ACM CCS 2025 accounted for real-world conditions: room echo, frequency loss, microphone distortion. They crafted adversarial audio robust enough to survive being played from a speaker across the room. Success rates held at 87-88% in physical tests. Background audio playing during a conference call injects instructions into the meeting transcription system. Nobody in the room hears anything unusual.
Your text-layer monitoring sees clean audio. The log looks normal. The model already executed the injected command.
We dropped the free chapters. Now breach the wall for the dead-simple step-by-step kill switch that shuts this all down.
